Introduzione
La funzionalità di replica di SQL Server è uno strumento avanzato che consente di tenere perfettamente sincronizzati due o più database, anche tra server diversi e tra posizioni geografiche diverse. La replica transazionale mediante la modalità cosiddetta “Peer To Peer” consente la copia automatica e bidirezionale dei dati tra più istanze di SQL Server, chiamate “nodi”. Ogni nodo agisce sia come “Publisher” che come “Subscriber”, ricevendo ed inviando le transazioni agli altri nodi. Si tratta di una soluzione per la scalabilità orizzontale ad elevate prestazioni: le applicazioni che richiedono scalabilità orizzontale possono distribuire le operazioni di lettura su più nodi. Questo garantisce una elevata disponibilità del dato. Viceversa le operazioni di scrittura devono essere gestite a livello di singolo nodo, al fine di evitare conflitti. Inoltre, questa tipologia di replica, garantisce che l’indisponibilità di un nodo (per errori o per attività di manutenzione) non pregiudichi il funzionamento e la disponibilità dell’intera architettura.
La replica è quindi anche una forma di backup o di failover per database SQL Server che devono avere un uptime sempre garantito.
Vedi anche: Backup di database SQL Server con Iperius Backup
La replica “Peer To Peer” è disponibile solo nelle versioni Enterprise di SQL Server. Di seguito vedremo in dettaglio i singoli passaggi per configurare una replica, tra tre nodi, di istanze database SQL server installate su server differenti. Vedremo successivamente come aggiungere un ulteriore nodo alla replica.
Glossario degli elementi:
Nel presente articolo si farà riferimento ai seguenti elementi per indicare:
- Distributore (distributor) (Installazione di SQL server che memorizza i dati al fine di renderli disponibili alla pubblicazione )
- Pubblicatore (publisher) (Installazione di SQL Server origine dei dati)
- Sottoscrittore (subscriber) (installazione di SQL Server destinataria dei dati)
- Pubblicazione (publication) (dati da replicare)
- Nodo (singola installazione di SQL server che concorre nella replica)
- Articoli (elenco di oggetti (tabelle, stored procedure) inseriti nella pubblicazione)
Supponiamo di avere tre istanze di SQL Server in ascolto su tre differenti server:
- SERVER-ASIA-1
- SERVERNORDAMERICA-1\SERVERNORDAMERICADB
- SERVERITALIA\SERVERITALIADB
nel presente esempio la versione installata è per tutti SQL Server 2017 Enterprise.
Tutte le istanze di SQL Server coinvolte sono state configurate su una porta differente della 1433, per motivi di sicurezza. Attraverso il Configuration Manager di SQL Server, cliccando su “Configurazione di rete SQL Server” è possibile cambiare la porta (è necessario riavviare il servizio di SQL Server) :
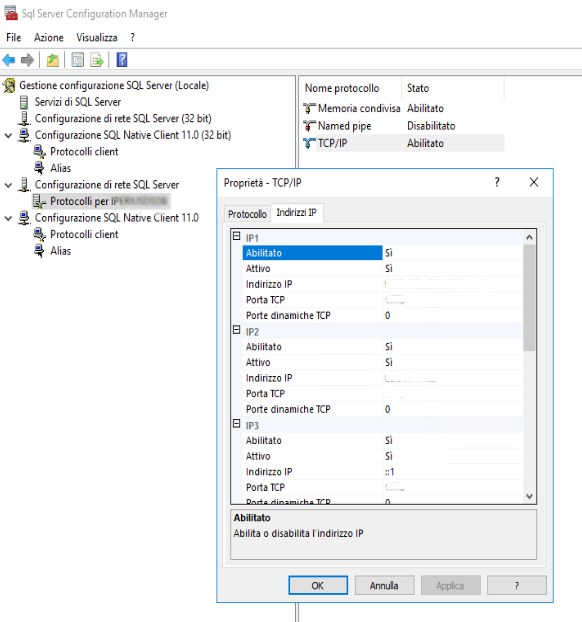
quindi si rende necessario, su ogni nodo, configurare degli Alias per gli altri nodi. Si possono configurare gli alias attraverso l’utilizzo del Configuration Manager:
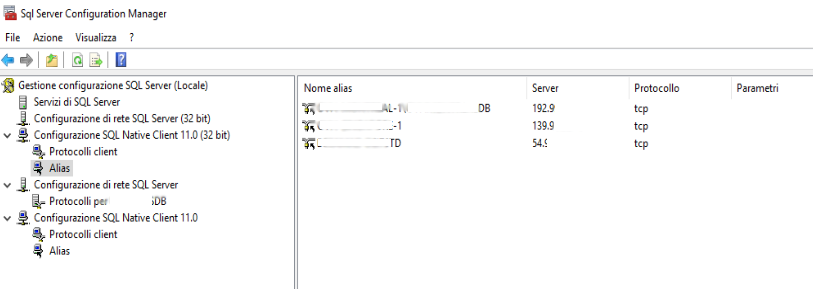
è importante specificare un “Nome alias” identico all’istanza SQL Server di destinazione, in caso contrario la replica non riuscirà ad individuare il peer corrispondente.
Ogni server/istanza deve avere attivi ed impostati ad avvio automatico i servizi:
- SQL server
- SQL Server Agent
- SQL Server Browser
se i server che ospitano i nodi sono protetti da Firewall, è necessario consentire l’accesso per il protocollo TCP, sulla porta configurata, per le connessione in ingresso.
Configurazione Distribuzione
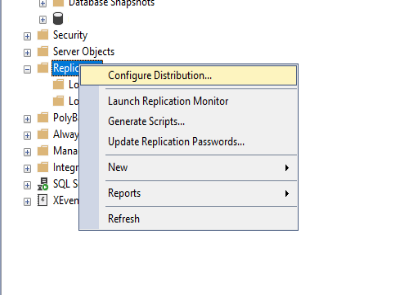
Come primo step è necessario configurare ogni nodo come distributore cliccando su “Replica–>Configura distribuzione…”
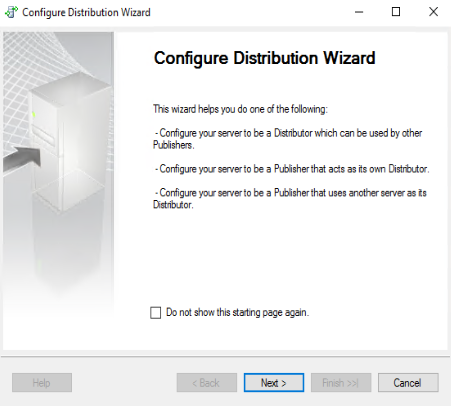
Scegliamo la prima opzione: il server di Distribuzione è l’istanza corrente. Eventualmente si può scegliere come distributore un’istanza di SQL Server differente, precedentemente configurata come Distributore. Cliccare su “Next >”
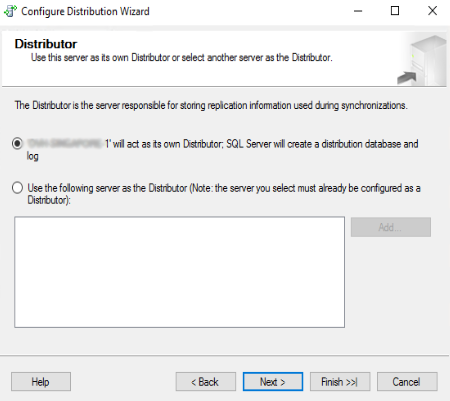
Nella successiva schermata scegliere il percorso dello snapshot e cliccare su “Next >”
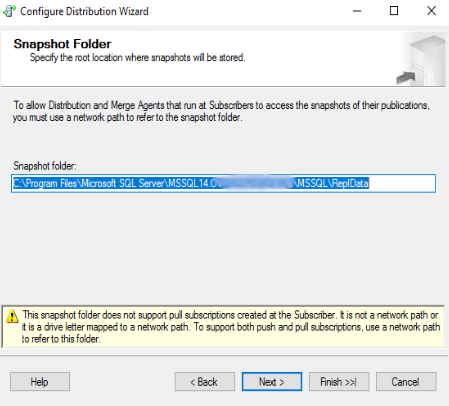
Successivamente il wizard chiede di indicare il nome del database di distribuzione. Requisito fondamentale è che, per tutti i nodi, i database di distribuzione abbiano lo stesso nome. Nel presente esempio, i valori di default proposti, per le directory del database e del log, non devono essere cambiati
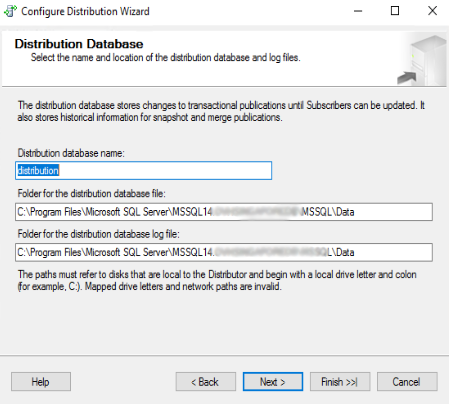
Nella successiva schermata si abilita il server corrente ad utilizzare il database di distribuzione, precedentemente creato, quando lo stesso diventerà un pubblicatore. Cliccare su “Next >”
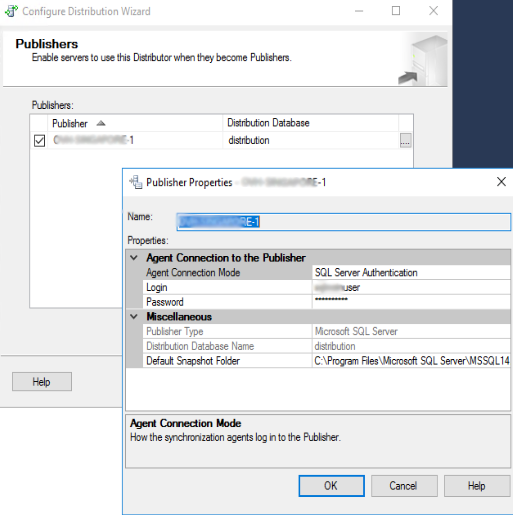
Nella Form successiva è possibile scegliere se creare subito la distribuzione, oppure generare il relativo script. Scegliamo la prima opzione e clicchiamo su “Next >”
Viene proposto il riepilogo, accertarsi che tutte le informazione siano corrette e cliccare su “Next >”.
Il wizard creerà la distribuzione.
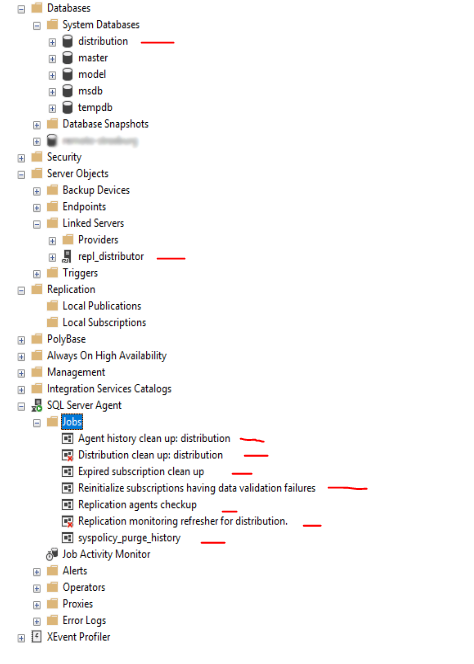
L’effetto, come si vede dalla schermata successiva è la creazione di:
- Creazione del database “distribution” tra i database di sistema ;
- Creazione del Linked Server “repl_distributor”;
- Creazione di specifici JOB di SQL Server Agent per le funzionalità di replica.
Configurazione Pubblicazioni
Create le distribuzioni è necessario inizializzare la pubblicazione. Scegliere uno dei server come Nodo Principale e cliccare su “Local Pubblication > New Publication”
Appare il wizard per la creazione di una nuova Pubblicazione. Cliccare su “Next >”:
Scegliere il database da replicare e cliccare su “Next >”:
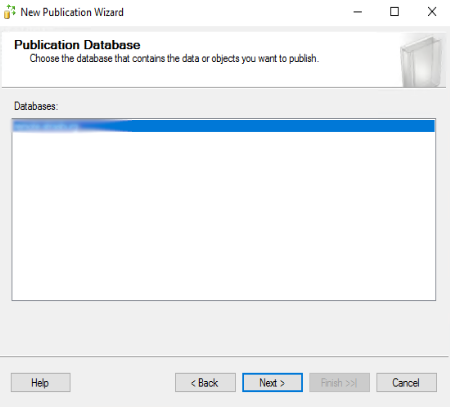
Scegliere come tipologia di pubblicazione “Peer-To-Peer publication” e cliccare su “Next >”:
Nella schermata successiva si devono scegliere gli Articoli, ovvero le Tabelle e le Stored Procedure da includere nella replica. Su “Article Properties” è possibile configurare la modalità (Conversione di Tipi di Dati) e la tipologia (Indici, Partizioni, Chiavi ecc..) degli oggetti che devo essere gestiti nella replica. Le impostazioni di default comprendono una gamma sufficientemente ampia e funzionale per una corretta replica.
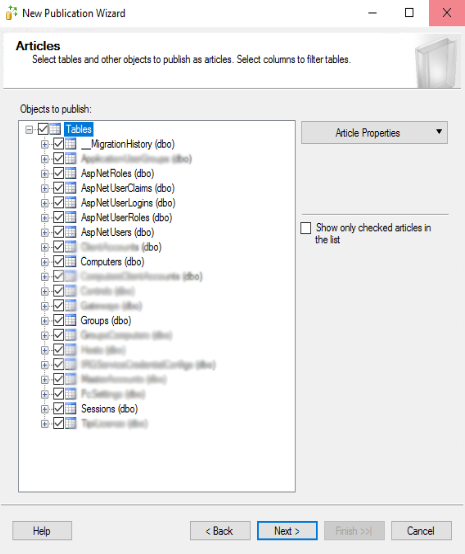
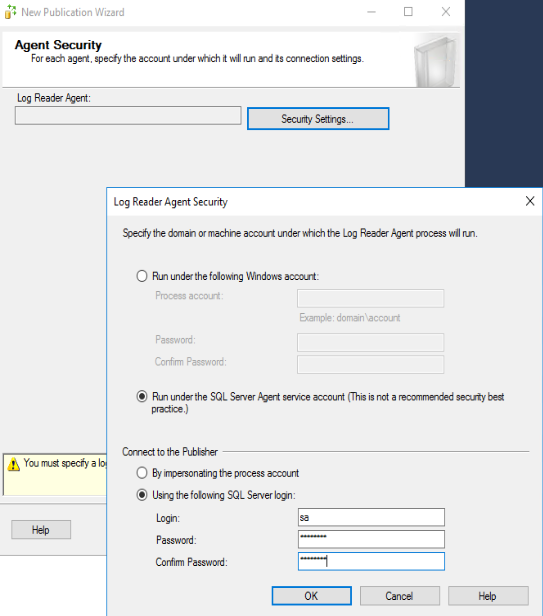
Nello step seguente si devono specificare le impostazioni di sicurezza con le quali viene eseguito il processo dell’agent del Log. La soluzione consigliata sarebbe creare un utente specifico per tale attività. Tuttavia in questo esempio è sufficiente selezionare “Esegui con L’account di SQL Server Agent”. Nella sezione “Connessione al Pubblicatore”, specificare un account di tipo “sa” (System Administrator) per connettersi al database. Cliccare su “Next >”
Come per la Distribuzione, il wizard chiede di scegliere se creare subito la pubblicazione o generare uno script. Proseguiamo con la prima scelta e creiamo la pubblicazione.
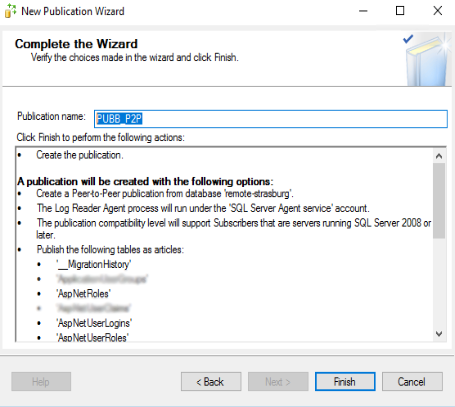
Al click del “Next >” appare il riepilogo, come da immagine successiva, dove è necessario specificare anche il nome della pubblicazione. Digitiamo “PUBB_P2P” e clicchiamo su “Next >”
Il wizard genera la Pubblicazione, per gli articoli del database scelti.
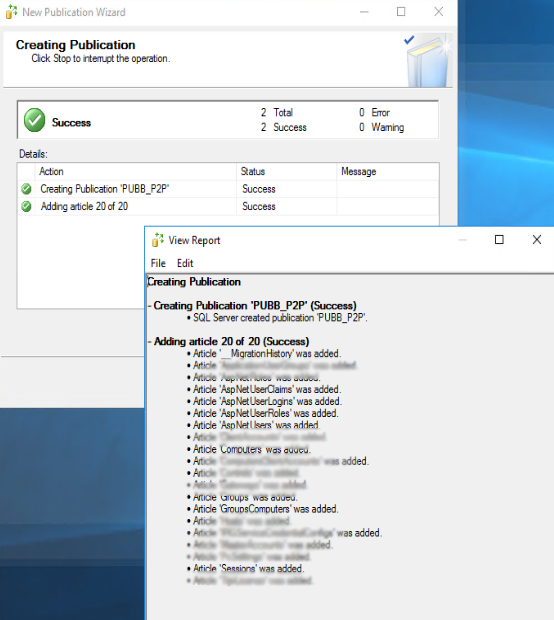
Sul SQL Management Studio il risultato è il seguente:
Suggerimento: Opzione Continua Replica dopo un conflitto rilevato
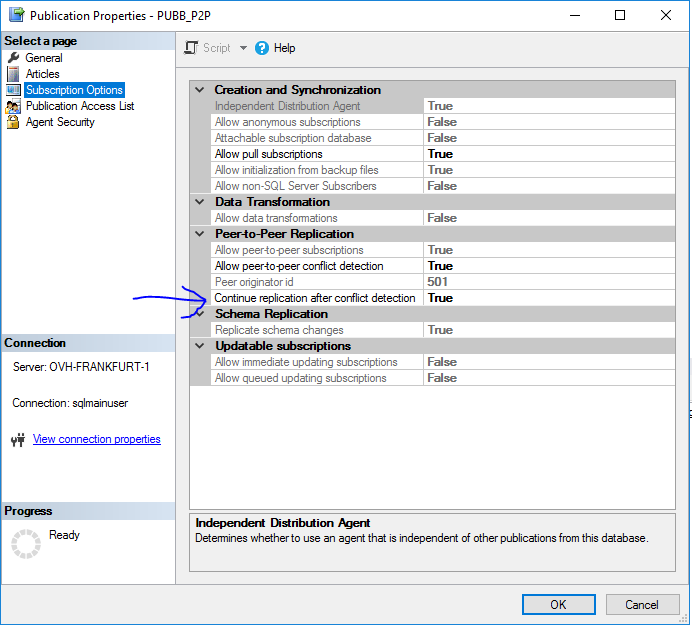
Cliccando sulle proprietà della pubblicazione – operazione da eseguire su tutti i nodi della replica peer to peer – tra le impostazioni quella su cui dobbiamo fare alcune considerazioni è la: “Continue replication after conflict detection”. E’ consigliabile settare la proprietà a “true” sulle pubblicazioni di tutti i nodi perchè – ammesso che il “software layer” acceda in maniera correttamente partizionata al “database layer” – possono comunque verificarsi conflitti nella replica che di fatto impedirebbero la propagazione dei record sugli altri nodi.
Questo sistema, molto simile ad una “fault tolerance”, permette di gestire senza troppi errori la replica dei record e prevenire il disallineamento dei dati sui diversi database dei nodi.
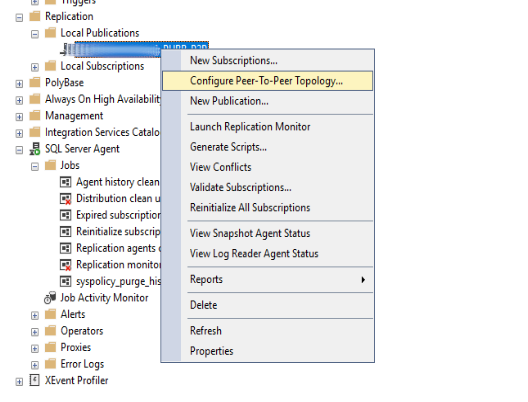
Configurazione Tipologia Replica Peer To Peer
Non resta che cliccare con il pulsante destro sulla pubblicazione appena creata e selezionare la voce di menù “Configura Tipologia Peer To Peer … ”
da cui appare la schermata iniziale del wizard. Cliccare su “Next >”
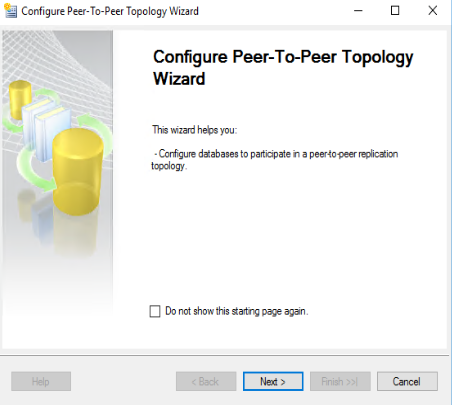
si accede alla schermata di selezione della Pubblicazione con la è possibile iniziare la configurazione della tipologia Peer-To-Peer. Avendo scelto come “Publisher” principale il Server corrente, selezioneremo la relativa pubblicazione, precedentemente configurata. Cliccare su “Next >”
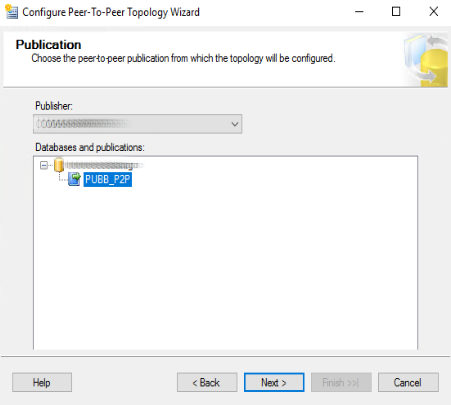
La schermata seguente mostra lo schema del peer-to-peer. Al momento appare un unico nodo, il Publisher Server. Cliccando sullo sfondo grigio, con il pulsante destro, appare il menù contestuale. Il nostro scopo è quello di aggiungere un nuovo nodo “peer-to-peer”. La voce da selezionare è “Add a New Peer Node”.
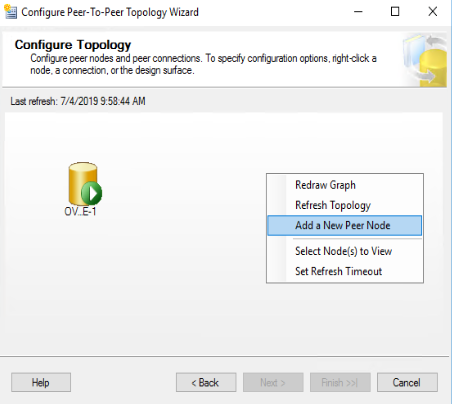
Nella nuova finestra di dialogo che appare, occorre autenticarsi sulla istanza di SQL Server che ospita il nodo. E’ bene fare attenzione a questo passaggio. Il “server name” che si specifica nella connessione deve essere assolutamente identico al nome dell’istanza a cui ci si connette. Risulta utile, nel caso il server di destinazione fosse in ascolto su una porta diversa da quella di default (1433), configurare opportuni “alias”, attraverso il Configuration Manager di SQL server, facendo si che l’alias sia identico al nome dell’istanza remota.
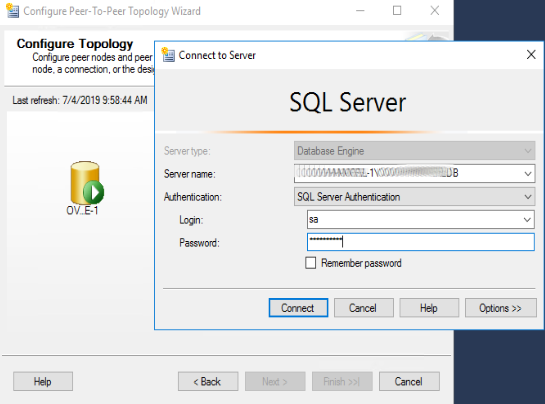
eseguita con successo l’autenticazione, viene mostrata la schermata di configurazione del nodo. Selezioniamo il database remoto e impostiamo l’”originator Peer Id” a “201” (questo codice è l’identificativo dell’oggetto all’interno di Sql server. Il codice è importante per determinare, in fase di risoluzione dei conflitti, quale nodo abbia la precedenza. Viene mantenuto il valore del nodo con codice più alto). Selezioniamo “Connect to ALL displayed nodes”. Lasciare “Use Push subscription”. Come già detto in precedenza, in una replica peer-to-peer, tutti i server sono configurati come Distributor, quindi i Replication Agents (Job di SQL server) vengono creati su ciascun Nodo. Specificare una subscription di tipo “Push” sta a significare che gli Agent risiedono tutti sui Distributor ed ogni volta che vengono eseguiti inviano (“Push”) i dati cambiati ai Subscriber. Viceversa, nel caso di subscription di tipo Pull, i Replication Agents (Job di SQL server) risiedono nei Subscriber e sono questi ultimi ad interrogare i Distributor per nuova variazioni ed in caso affermativo li “scaricano” (Pull).
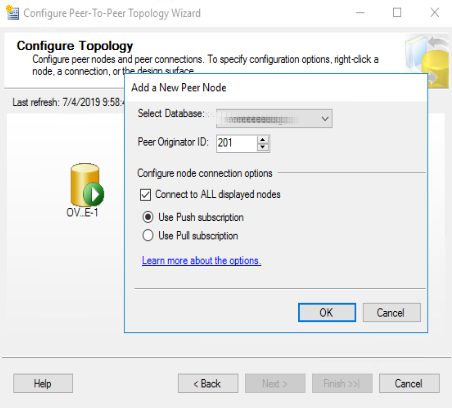
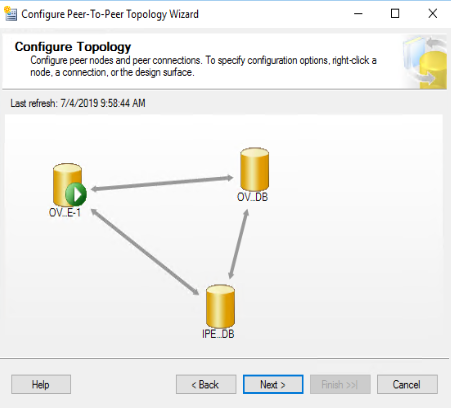
Questa operazione di aggiunta va fatta per tutti i nodi che decidiamo di includere nella replica peer-to-peer. Ovviamente è buona pratica specificare un “Peer Originator ID” diverso per ogni nodo. ad esempio sul secondo possiamo inserire “301”, sul terzo “401” e così via. Il risultato è quello mostrato sotto, lo schema a stella di una replica peer-to-peer.
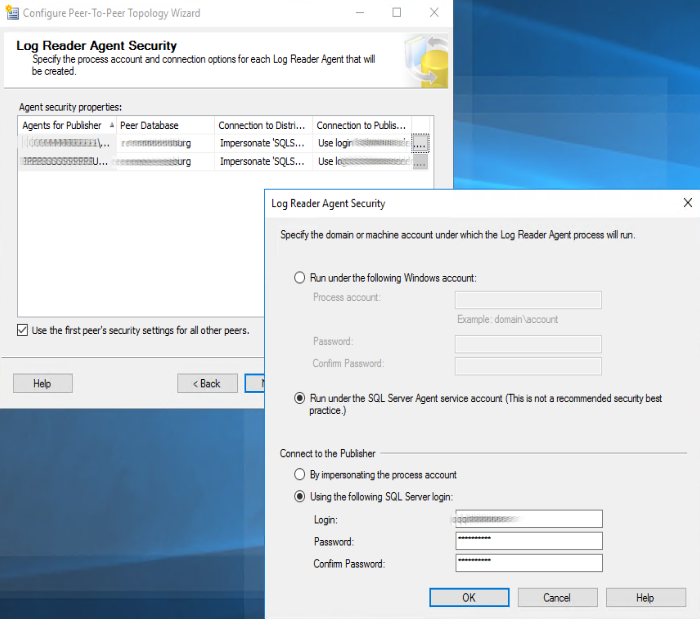
Cliccando su “Next >” è il momento di configurare i permessi di esecuzione e di accesso. La prima cosa da specificare è l’account di accesso per il Log Reader di SQL server Agent. La pratica consigliata è quella di creare un account dedicato con permessi sufficienti a completare l’operazione richiesta, tuttavia possiamo, nel nostro esempio, Indicare “Run Under the Sql Server Agent Account ” e specificare, nella sezione “Connect to Publisher”, “Use The Following SQL Server Login” (nell’esempio è stato inserito l’account sysadmin).
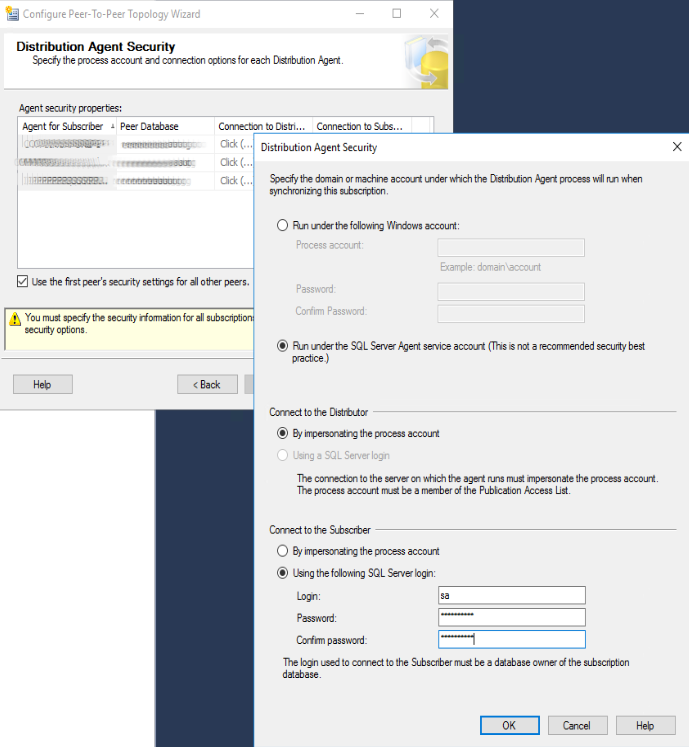
Selezionando “Use the first peer’s security setting for the others” si può evitare di replicare il passaggio precedente e usare la stessa configurazione per tutti gli Agent. Dunque clicchiamo su “Next >” e si arriva alla schermata di configurazione della security per i distribution Agent. Come per la configurazione precedente, nel nostro esempio, indichiamo “Run Under the Sql Server Agent Account ” e specifichiamo, nella sezione “Connect to Subscriber”, “Use The Following SQL Server Login” (nell’esempio è stato inserito l’account sysadmin). In questo caso la sezione si chiama “Connect to Subscriber” perchè avendo scelto in precedenza la replica di tipo “Push” sarà il nostro distributor agent a connettersi ai subscriber e non viceversa. Anche in questo caso possiamo selezionare “Use the first peer’s security setting for the others”. Clicchiamo su “Next >”.
Nella maschera successiva selezioniamo “I created the peer database manually, or i restored a backup…” e clicchiamo su “Next >”
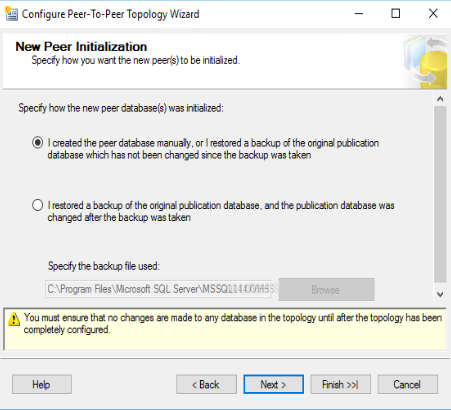
Nel caso invece si voglia configurare una replica su database ripristinato manualmente però cambiato successivamente al ripristino occorre selezionare la seconda opzione e specificare il file di backup originario. Sarà il wizard ad allineare le basi dati. Noi però procediamo con la prima opzione.
Il wizard ci mostra, nel successivo passaggio, il riepilogo delle configurazioni/oggetti che verranno creati, sia sui Publisher che sui Distributor, nonché tutte le operazioni sequenziali che verranno eseguite.
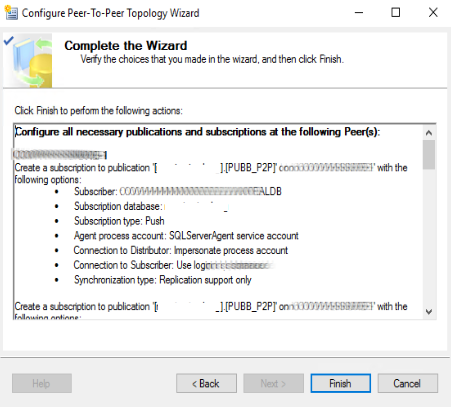
La schermata successiva ci darà conferma di tutte le operazioni eseguite e del loro esito. Verranno create le pubblicazioni su tutti gli altri nodi (sul corrente l’abbiamo creata manualmente) e su tutti i nodi verranno create le subscription rispettivamente per ogni altro nodo inserito nella configurazione. Due per ogni server per un totale di 3 (nodi) x 2 (Subscription) = 6 (Subscription).
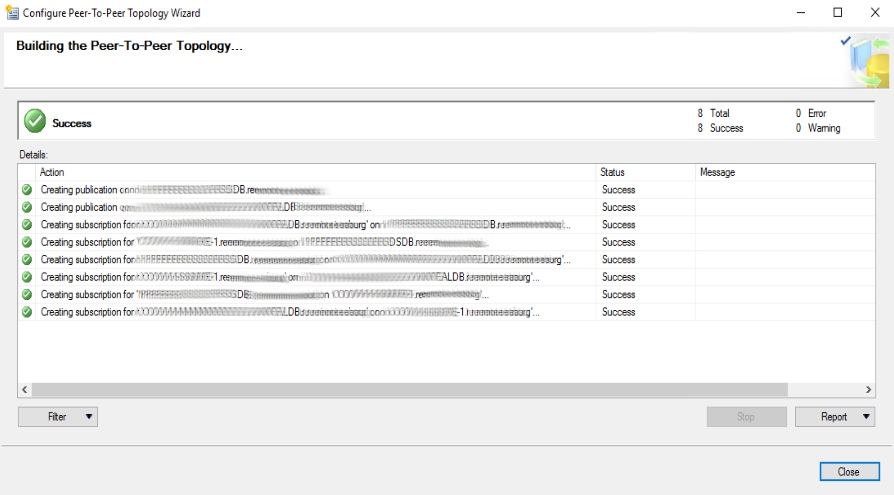
E’ possibile in qualsiasi momento aggiungere un nodo ad una replica Peer To Peer esistente.
PLEASE NOTE: if you need technical support or have any sales or technical question, don't use comments. Instead open a TICKET here: https://www.iperiusbackup.com/contact.aspx
**********************************************************************************
PLEASE NOTE: if you need technical support or have any sales or technical question, don't use comments. Instead open a TICKET here: https://www.iperiusbackup.com/contact.aspx
*****************************************