Dans cet article, nous allons approfondir la différence entre une image Docker et un conteneur et créer notre Dockerfile pour mieux comprendre les différentes phases de la virtualisation des conteneurs Docker.
Nous avons déjà parlé de ce système dans un tutoriel où nous avons appris à installer Docker.
Mais pourquoi parler d’images et de conteneurs ?
Docker image e container
Pour mieux comprendre quelles sont les différences entre les images et les conteneurs, essayez de penser à un langage orienté objet. Dans une telle analogie, la classe représente l’image tandis que son instance, l’objet, est le conteneur.
La même image peut créer plusieurs conteneurs.
La virtualisation des conteneurs repose donc fondamentalement sur les images, les fichiers disponibles sur le Docker Hub et utilisés pour créer et initialiser une application dans un nouveau conteneur Docker.
Chaque image est définie par un Dockerfile, un fichier de configuration contenant toutes les commandes qu’un utilisateur doit exécuter pour modéliser l’image.
Les couches du Dockerfile
Le dockerfile est un outil puissant pour définir des images grâce à sa structure en couches, qui contient des commandes, des bibliothèques à utiliser et des dépendances.
Certaines couches peuvent se trouver dans plusieurs projets, cette caractéristique garantit donc la réutilisation de ce qui a déjà été téléchargé et par conséquent une garantie sur les performances et, non moins important, un gain de temps et d’espace physique.
Supposons, par exemple, que nous ayons besoin d’utiliser les images de deux SGBDR tels que PostgreSQL et MySQL (ou MariaDB).
D’abord, nous commençons à chercher, avec la commande docker search, les images officielles contenues sur le dockerhub pour ces deux systèmes et ensuite nous prenons les images officielles.
#docker search postgresql
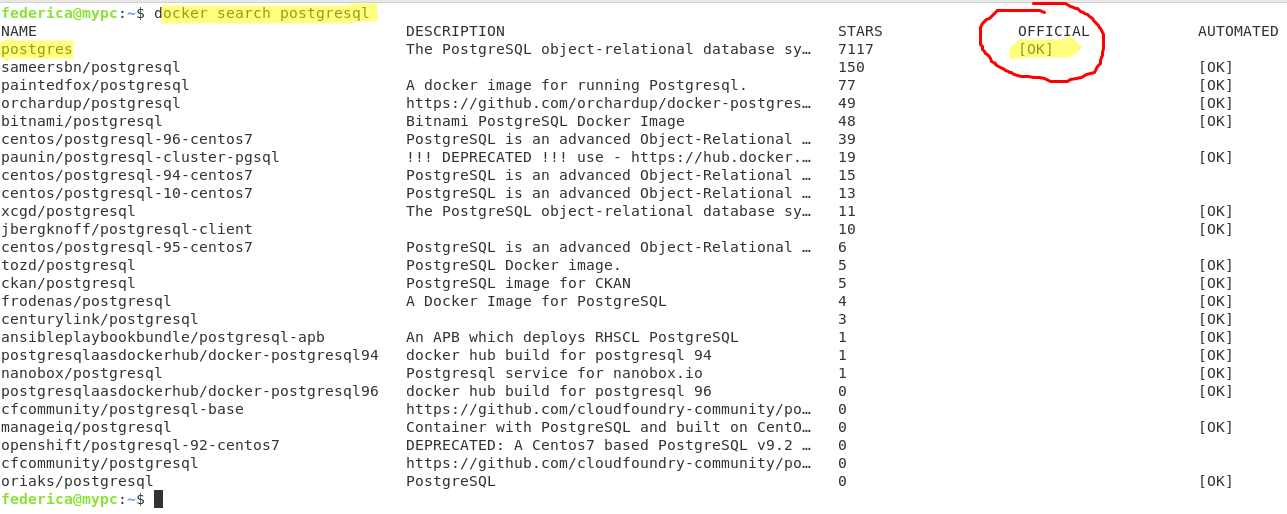
#docker search mysql

Dans ce deuxième cas, nous pouvons choisir soit MySQL, soit MariaDB.
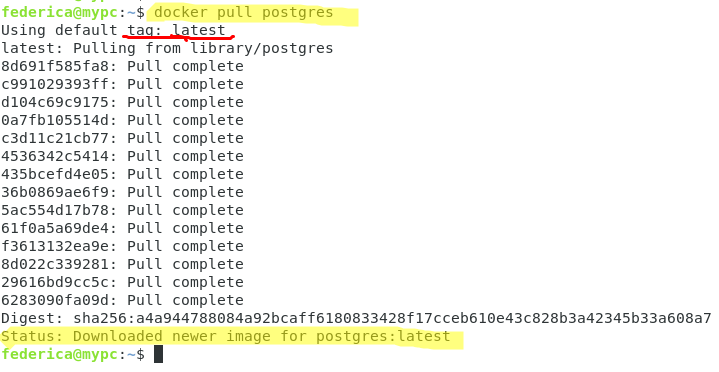
Nous choisissons ce dernier, et avec la commande docker pull nous téléchargeons les images localement depuis le DockerHub.
# docker pull postgres
#docker pull mariadb
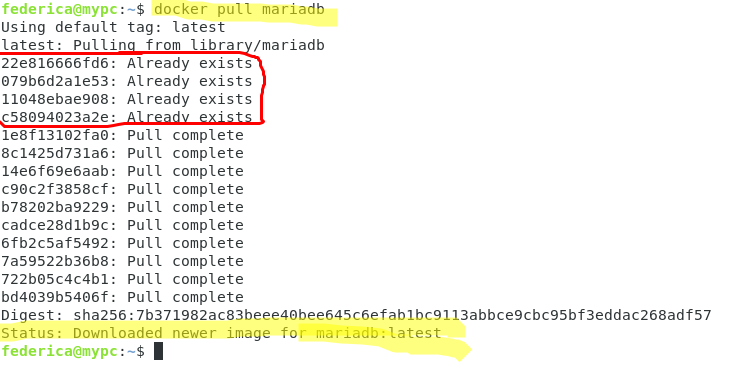
Nous pouvons observer que le statut final indique le téléchargement correct des images (dernière version – identifiée par le tag par défaut) et que dans les deux cas, ils sont composés de 14 couches distinctes.
Nous remarquons cependant que dans le cas de MariaDB, les quatre premières couches sont indiquées par “Already exists”. En fait, elles avaient déjà été téléchargées lors d’un précédent pull, et il n’est donc pas nécessaire de les re-télécharger.
Un identifiant distingue chacune de ces couches tandis que l’avant-dernière chaîne “Digest” représente de manière univoque l’image qui vient d’être téléchargée en tant que hachage de l’image elle-même.
Pour mieux comprendre cet aspect des couches Docker, voyons comment construire un DockerFile.
Construire un DockerFile
Si nécessaire, il est possible de créer ses propres Dockerfiles, en ajoutant des niveaux à une image de base – celle qui représente la base de départ – ou à partir d’une image vide en cas de besoin d’une liberté ultime de gestion.
Dans les deux cas, la première ligne contiendra la commande FROM, qui indiquera l’image de base (scratch dans le cas d’une image vide).
Prenons l’exemple d’un Dockerfile simple dérivé d’une image officielle ubuntu.
Nous créons notre Dockerfile avec notre éditeur préféré et ajoutons les lignes suivantes :
FROM ubuntu RUN apt-get update RUN apt-get install --yes apache2 COPY index.html /var/www/html/index.html
Au premier niveau (FROM ubuntu), nous ajoutons trois niveaux qui représentent les commandes que nous voulons ajouter.
Nous exécutons la commande build pour construire l’image telle que décrite dans le fichier de la manière suivante :
#docker build.
N’oubliez pas le point (.) qui indique le répertoire courant où docker recherche un dockerfile, exactement avec ce nom.
Comme vous pouvez le voir sur les images ci-dessous, l’opération de build se compose de 4 étapes, qui correspondent aux quatre couches de notre image.
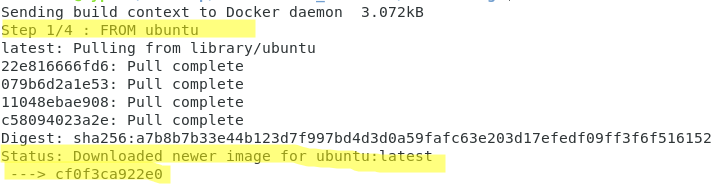
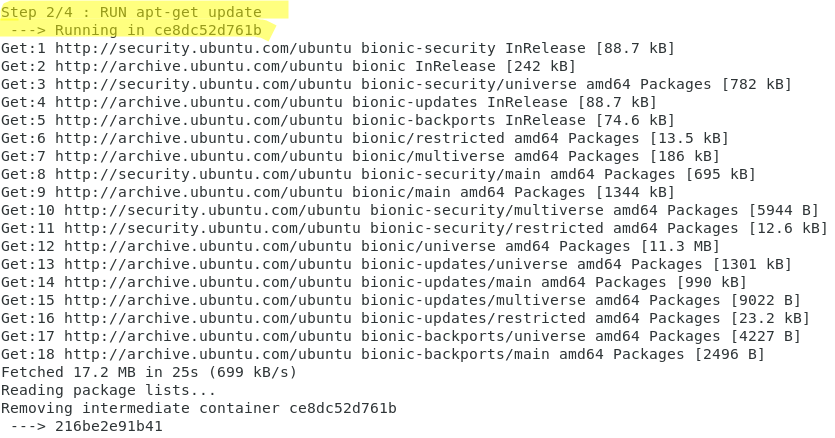


En fait, des niveaux intermédiaires seront construits, qui ont une fonction de cache dans les exécutions suivantes, comme on peut le voir dans la commande :
#docker images -a

Les images identifiées par dans la colonne repository sont les images intermédiaires.
Pour mieux comprendre, essayons de ré-exécuter la commande maintenant
#docker build
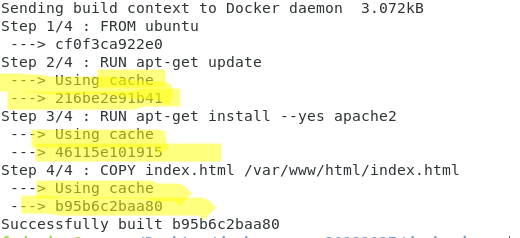
Il est facile de vérifier que la construction des images est maintenant beaucoup plus rapide et qu’elle réutilise les images déjà mises en cache.
L’image 46115e101915, par exemple, est celle qui est réutilisée à l’étape 3/4.
Conteneurs
Jusqu’à présent, nous avons parlé de la manière de télécharger une image ou de construire et mettre en œuvre la vôtre.
Mais c’est avec la commande “docker run” que tout prend vraiment forme.
#docker run --rm --name ubuntu_apache -it ubuntu
![]()
En fait, cette commande permet d’instancier un conteneur sur l’image nouvellement créée.
Les options choisies dans ce cas sont celles relatives à l’interactivité (-i), à l’attribution d’une console TTY (-t) et à la possibilité de supprimer directement le conteneur après la sortie (-rm).
La documentation officielle de Docker contient la liste de toutes les options de la commande run.
Alors que l’image est constituée d’une série de couches toutes en mode lecture seule, le conteneur ajoute une couche supérieure (également appelée couche conteneur) en mode lecture-écriture.
Et chaque fois qu’un nouveau conteneur est instancié sur la même image, une nouvelle couche est ajoutée pour créer de nouveaux conteneurs.
Si nous voulons avoir une liste des conteneurs actifs et non actifs, nous pouvons exécuter la commande :
#docker ps -a

L’utilisation de conteneurs est utile car vous pouvez facilement et rapidement construire un environnement de développement ou de test aussi souvent que vous le souhaitez.
En quittant la console avec la commande exit, le conteneur, grâce à l’option -rm, n’existera plus.
Essayons maintenant d’utiliser la commande :
#docker run --name ubuntu_apache -it ubuntu
sans l’option de suppression précédente.

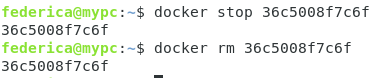
À ce stade, si nous voulions le supprimer manuellement, nous devrions utiliser la fonction :
#docker rm
suivie de l’identifiant.
Mais pas avant de l’arrêter.
La séquence correcte des commandes est donc la suivante :
Si, à la place, nous voulions redémarrer le conteneur précédemment arrêté, la commande à utiliser est la suivante :
#docker start
et dans notre cas d’exemple, ce serait :
![]()
Conclusions
Dans cet article, nous avons pu comprendre, à partir de quelques exemples, comment il est facile de mettre en place des environnements parfaitement fonctionnels, réplicables sur n’importe quelle machine en utilisant l’évolutivité du système de couches des images Docker.
Plus tard, nous parlerons de la façon d’augmenter le potentiel de cet outil avec des mécanismes puissants tels que Docker-compose et Docker-swarm.
Crédits images :
PNG métal conçu par Mark1987 à partir de Pngtree.com
Icône Docker réalisée par Freepik à partir de www.flaticon.com
PLEASE NOTE: if you need technical support or have any sales or technical question, don't use comments. Instead open a TICKET here: https://www.iperiusbackup.com/contact.aspx
**********************************************************************************
PLEASE NOTE: if you need technical support or have any sales or technical question, don't use comments. Instead open a TICKET here: https://www.iperiusbackup.com/contact.aspx
*****************************************