Microsoft SQL Server est une base de données possédant de nombreuses fonctionnalités concernant la réplication, la mise en miroir et le clustering avec basculement.
Toutes sont des stratégies ou des configurations dont le but est, avec différentes manières d’agir, de rendre les données toujours disponibles pour les applications clientes, en cas de plantage ou de mauvais service. Elles servent aussi a répliquer les données dans des différents endroits géographiques, pour augmenter les performances en matière d’accessibilité et de disponibilité.
Dans ce tutoriel, nous ne parlerons pas de cluster de basculement ou de groupes de disponibilité toujours activés, qui sont tous deux des procédures de mise en miroir de base de données dans le but d’assurer la disponibilité continue de tous les services en cas de dysfonctionnement ou de panne de serveur.
Au contraire, nous allons nous concentrer sur les procédures de réplication de la base de données, c’est-à-dire toutes les configurations qui permettent aux utilisateurs de répliquer toutes les données sur plusieurs serveurs SQL, de manière automatique et en temps réel.
SQL Server fournit 4 types de procédures de réplication :
- Transaction
- Fusion
- Cliché instantané
- “Entre homologue” (Peer to peer)
La “réplication entre homologues” est une solution permettant d’assurer haute disponibilité et montée en charge, car elle permet de gérer de nombreuses copies de données sur plusieurs instances du serveur, appelées «nœuds». Basé sur la réplication transactionnelle, la réplication Peer-to-peer propage les modifications de données à tous les nœuds et presque en temps réel. Grâce à cette redondance, les applications susceptibles de générer des montés en charges peuvent diviser les processus de lecture des clients en plusieurs nœuds et accéder plus rapidement aux données. Ce type de réplication est l’une des procédures de réplication les plus performantes et les plus «à l’épreuve des chocs», car le manque de disponibilité d’un ou de plusieurs nœuds n’affecte pas le fonctionnement et la disponibilité de l’ensemble du système lui-même.
Toutefois, la réplication entre homologues est disponible uniquement sur la version SQL Server Enterprise, avec des coûts de licence qui sont évidemment très élevés par rapport aux autres versions. Un bon choix alternatif, à la portée des petites et moyennes entreprises, et à la fois stable et flexible à configurer, est la réplication par fusion, dont nous parlerons maintenant.
Commençons donc immédiatement par la pratique, en commençant par ce dont nous avons besoin pour configurer une réplication par fusion, puis nous verrons comment la configurer en quelques étapes simples.
Considérons 3 SQL Server 2014, étant géographiquement distant et fonctionnant sur différents réseaux. Le schéma final que nous obtiendrons est celui montré sur l’image ci-dessous:
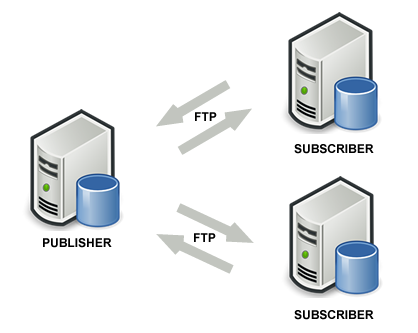
Il doit y avoir un serveur principal appelé Publisher (éditeur) et des serveurs secondaires appelés Subscribers (abonnés).
Les abonnés synchroniseront leurs propres données avec l’éditeur (envoi et réception) et, par conséquent, les données de chaque abonné seront également synchronisées avec les autres. Par conséquent, la première chose à faire est de décider lequel des trois serveurs agira en tant qu’éditeur puis de procéder à sa configuration, comme expliqué ci-dessous.
Tout d’abord, assurons-nous que le service SQL Server Agent est démarré et configuré en mode automatique, sinon nous allons l’exécuter.
ÉTAPE 1: Créer la publication sur le serveur Publisher
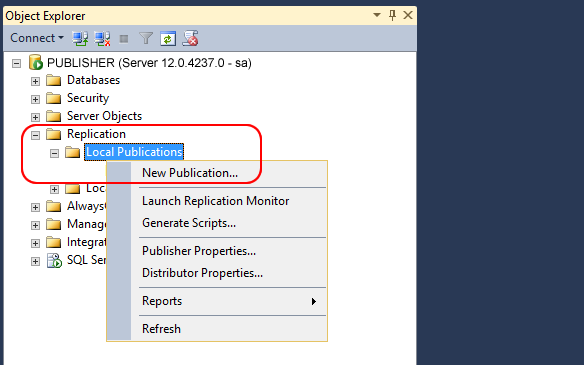
Nous allons commencer à configurer toutes les différentes options dans la fenêtre “Nouvelle publication Assistant”.
Passons maintenant directement à la première fenêtre:
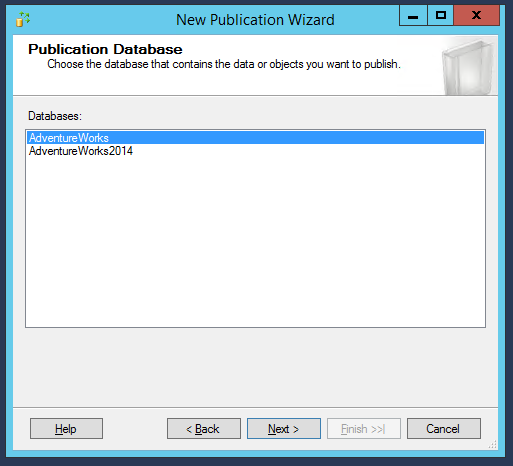
Maintenant, sélectionnons la base de données que nous voulons synchroniser :
Choisissons ensuite le type de réplication que nous voulons mettre en place, à savoir la ” publication par fusion “ :
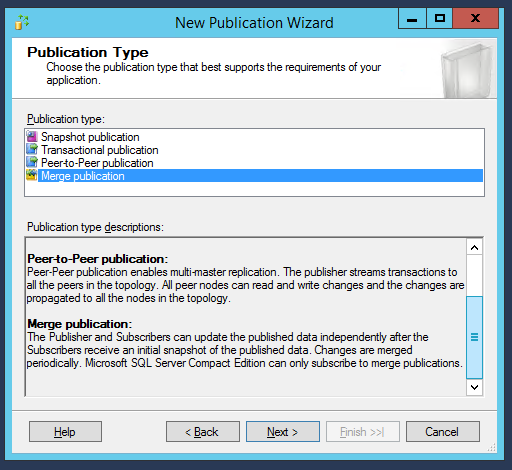
Dans la fenêtre suivante, nous garderons les options de compatibilité par défaut et continuerons en cliquant sur “Suivant” :
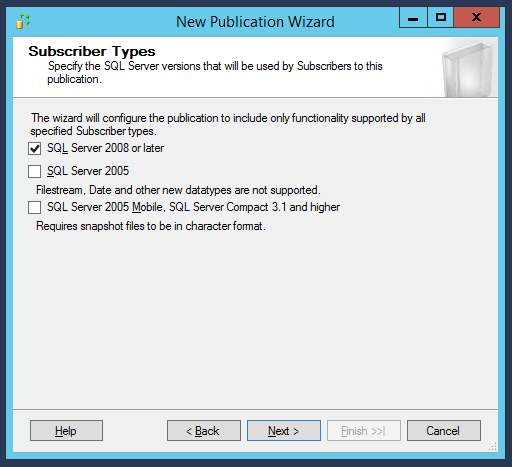
Maintenant, il y a une étape très importante de notre configuration : choisir les tables de base de données que nous voulons synchroniser. En les sélectionnant :
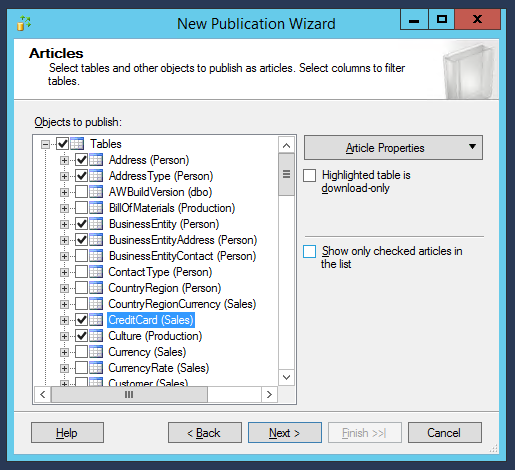
En passant à la fenêtre suivante, l’assistant nous avertira qu’un nouveau champ ID sera ajouté aux tables sélectionnées pour identifier les enregistrements de manière unique.
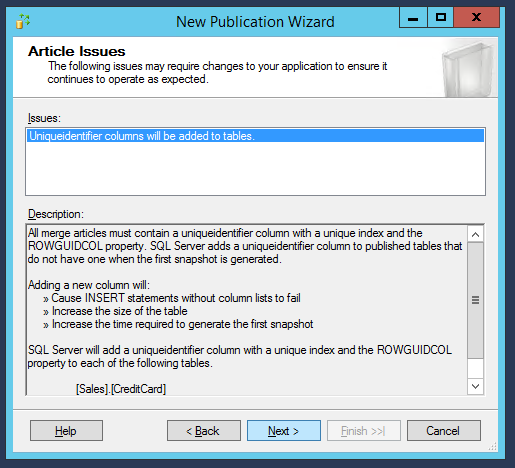
Passons maintenant à la fenêtre suivante, où l’on nous demandera si nous voulons ajouter des filtres aux données qui seront synchronisées. Dans ce tutoriel, nous n’utiliserons aucun filtre, alors continuons en cliquant sur “Suivant” :
Dans la fenêtre suivantes, conservons les deux options définies par défaut, puis cliquons sur “Suivant” :
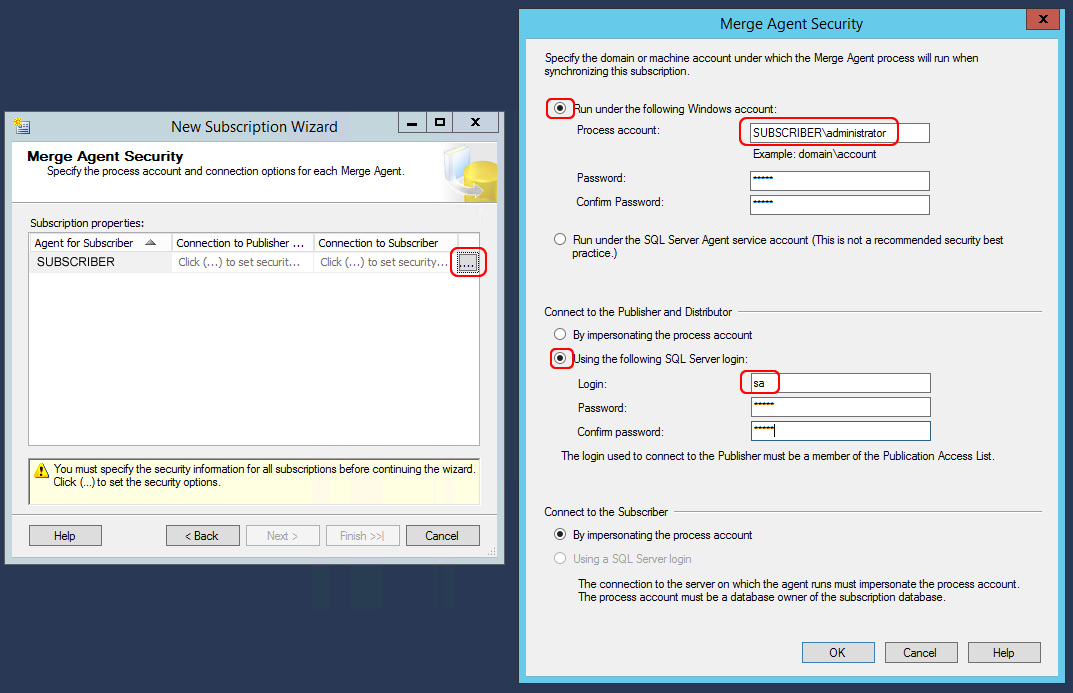
Maintenant, il y a une autre étape importante de notre installation, c’est la configuration des comptes pour exécuter le service de réplication (agent) et se connecter à l’éditeur, donc, dans ce cas, à lui-même.
Dans la fenêtre la plus à droite, écrivons le nom d’utilisateur du serveur, en plaçant le serveur ou le nom de domaine devant lui. Dans ce tutoriel, considérons que le nom du serveur est “PUBLISHER”.
Dans la fenêtre la plus à gauche, mettons le compte SQL Server, avec lequel il est possible de se connecter à la base de données avec un maximum de privilèges. Dans ce tutoriel, nous avons utilisé l’utilisateur SQL par défaut “sa”.
NB: la meilleure chose à faire est d’avoir le même nom d’utilisateur SQL Server et le même mot de passe sur tout le serveur de base de données (à la fois sur l’éditeur et sur les abonnés).
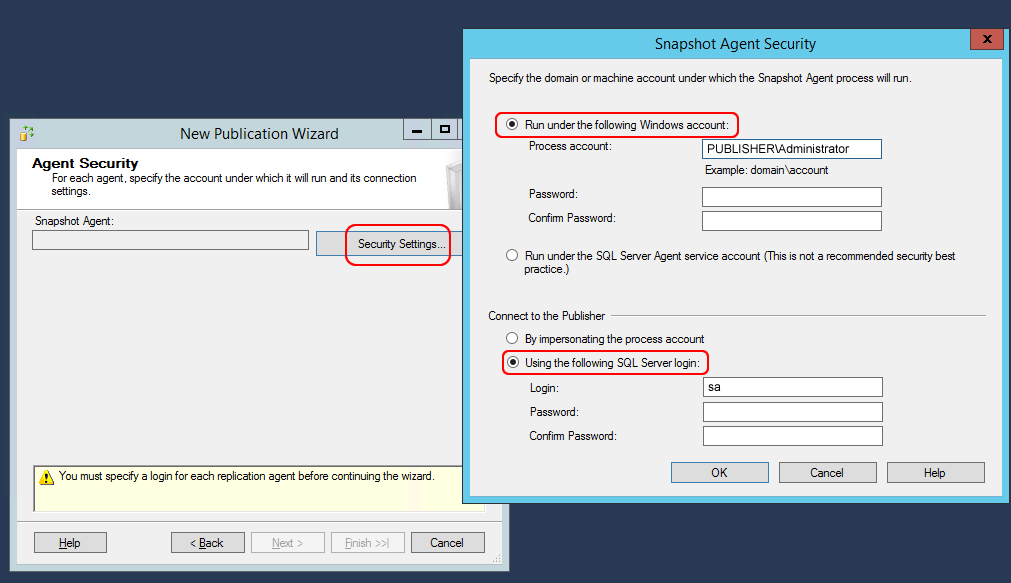
Confirmons tout en cliquant sur ok et passons à la fenêtre suivante.
Dans la cette dernière, nous allons cocher l’option “Créer la publication” et cliquer sur “Suivant” :
Enfin, le résumé de tous les paramètres sera affiché et nous pouvons maintenant créer la publication en cliquant sur “Terminer” :
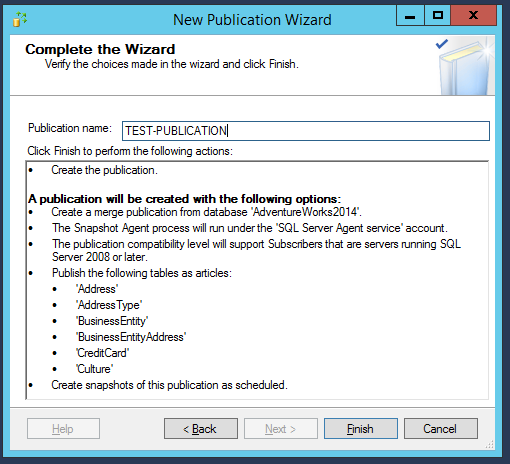
Une nouvelle fenêtre s’ouvre, indiquant la progression du cliché instantané initial, et les deux opérations doivent se terminer correctement.
ÉTAPE 2: Comment configurer le serveur “Publisher” pour permettre aux abonnés d’accéder aux données publiées ( Serveur FTP)
L’un des paramètres de réplication les plus fondamentaux est la façon dont les abonnés peuvent accéder aux données “publiées” par le serveur de l’éditeur. Physiquement parlant, l’éditeur crée périodiquement un instantané de ses données dans un dossier local, puis le met à jour avec des modifications de données. Par conséquent, nous devons nous assurer que les abonnés peuvent avoir un accès complet à cet instantané, afin qu’ils puissent synchroniser leurs données avec l’éditeur. Puisque dans notre tutoriel nous parlons de serveurs distants (donc pas à l’intérieur du même LAN), la façon dont nous avons choisi de rendre les données disponibles aux abonnés est le FTP (car il serait impossible d’utiliser un simple dossier partagé sur le réseau) .
Nous devons donc configurer sur l’éditeur un serveur FTP qui rend disponible à distance, pour les abonnés, le dossier où l’instantané de données reste. Nous pouvons utiliser le serveur FTP d’IIS, celui par défaut de Windows, ou un serveur tiers, comme FileZilla Server. Pour la configuration FTP dans IIS, reportez-vous au guide Microsoft officiel https://technet.microsoft.com/fr-fr/library/hh831655(v=ws.11).aspx
Premièrement, nous devons faire un changement à la publication que nous venons de créer, afin d’activer le FTP comme méthode d’accès aux données publiées :
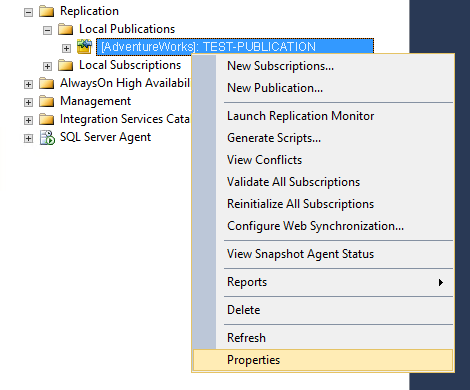
Continuons avec la configuration de la connexion (les paramètres doivent refléter la configuration du serveur FTP).
Écrivons le nom du serveur FTP (le même que le nom du serveur), le port (21 celui par défaut, mais pour des raisons de sécurité, nous pourrions en spécifier un autre), le nom d’utilisateur FTP et le mot de passe (si nous utilisons IIS , nous allons choisir un nom d’utilisateur Windows, en nous assurant qu’il s’agit d’un administrateur, au contraire si nous utilisons un autre serveur FTP, utilisons l’utilisateur que nous avons configuré à l’intérieur).
Enfin, spécifions le chemin relatif du dossier qui contient l’instantané, en le considérant comme commençant à la racine du serveur FTP.
Lors de la configuration de cette procédure, SQL Server crée (par défaut) un dossier appelé “ftp” (avec l’instantané de données à l’intérieur) dans le chemin “C: \ Program Files \ Microsoft SQL Server \ MSSQL12.MSSQLSERVER \ MSSQL \ repldata”. Ce chemin doit être configuré en tant que racine du serveur FTP et, par conséquent, le chemin relatif à définir dans cette fenêtre sera “/ ftp”, comme le montre l’image suivante :
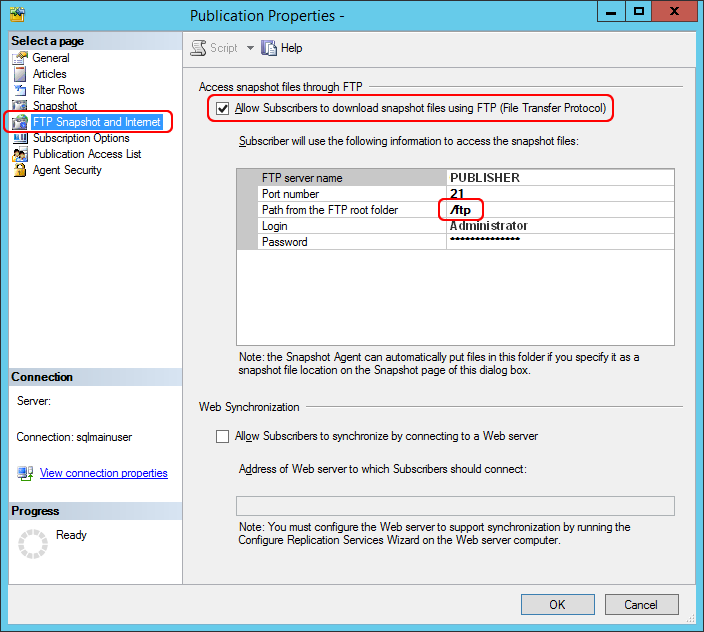
NB: il est nécessaire d’ouvrir le port FTP via une règle spécifique dans le pare-feu Windows.
Si des erreurs de connexion se produisent malgré la configuration correcte du pare-feu sur le serveur de publication, cela peut également être dû au pare-feu de l’Abonné. Pour vérifier cela, essayez de désactiver complètement le pare-feu de l’Abonné, puis réessayez la synchronisation. Ensuite, vous pouvez réactiver le pare-feu et ajouter les règles appropriées.
NB 2: une erreur dans la synchronisation (sur l’abonné) pourrait signifier que cette configuration FTP n’a pas été faite correctement. L’abonné, lors de l’accès aux données, peut rencontrer une erreur générique, entraînant une interruption anormale de l’agent / travail de synchronisation (des erreurs telles que «l’agent ne fonctionne pas» ou des plantages de mémoire). Dans ces situations, ne nous laissons pas induire en erreur par ces messages qui pourraient renvoyer à des problèmes complètement différents, mais vérifions à nouveau cette configuration. Un premier test pourrait être de se connecter à partir du serveur distant (un abonné) avec n’importe quel autre logiciel client FTP, comme FileZilla, pour être sûr que la connexion est OK et que les dossiers sont accessibles.
NB 3: le dossier “C: \ Program Files \ Microsoft SQL Server \ MSSQL12.MSSQLSERVER \ MSSQL \ repldata” et son sous-dossier relatif “/ ftp” peuvent ne pas être accessibles en raison de problèmes de permissions. En cas de problèmes qui ne semblent pas facilement reconnaissables, nous vous invitons à faire un test en mettant temporairement les autorisations de ce dossier sur “Tout le monde” -> “Contrôle total”.
Maintenant, toutes les configurations ont été effectuées. Vérifions avec “View snapshot status” que les instantanés sont correctement réalisés, et avec “Launch replication monitor” pour voir si les abonnés se synchronisent correctement (tant que nous n’aurons pas configuré d’abonné, il restera vide).
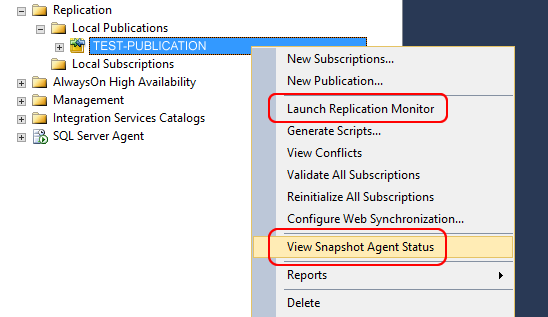
Si tout est correctement configuré sur l’éditeur, configurons maintenant un abonné, puis effectuons la première synchronisation des données.
ÉTAPE 3: Créer l’abonnement sur les abonnés
Condition préalable: vérifions que le service SQL Server Agent est en cours d’exécution sur les abonnés.
Passons maintenant au SQL Server qui se connectera au serveur principal en tant qu’abonné, puis synchronisera les données. Dans le menu “Réplication”, faites un clic droit sur “Abonnements locaux” puis sur “Nouveaux abonnements”.
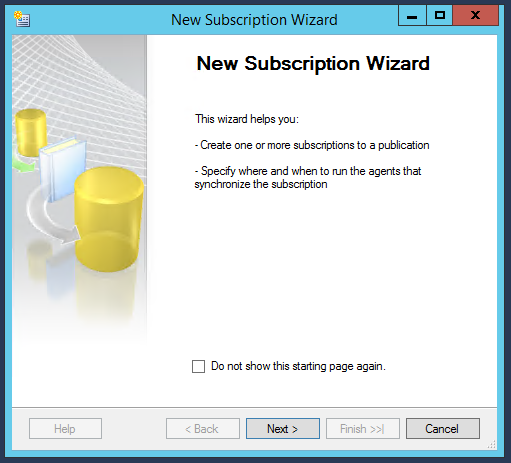
Dans la fenêtre suivante, nous devons nous connecter au serveur “Publisher” pour voir et sélectionner sa publication (celle que nous avons faite auparavant) :
Voici quelques étapes de configuration fondamentales à effectuer pour assurer une connexion correcte.
Lors de la recherche d’un éditeur, nous pouvons nous y connecter en spécifiant simplement le nom du serveur, mais pas l’adresse IP (avec ou sans port spécifique). Cela signifie que, sur ce système, nous devons “cartographier” en quelque sorte l’adresse IP du serveur de l’éditeur en utilisant son nom. Nous pouvons le faire en créant un alias avec les services SQL Server de la fenêtre de configuration, comme indiqué dans l’image ci-dessous :
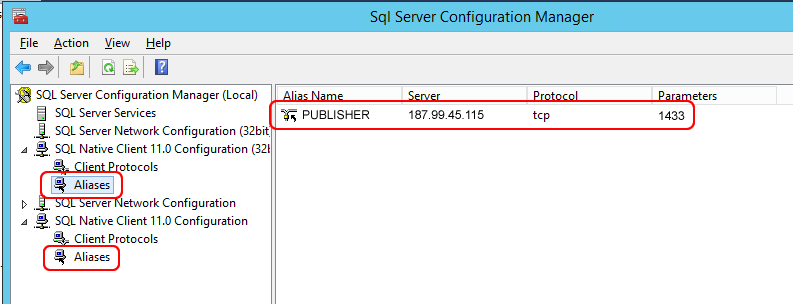
Ajoutons un alias avec le nom du serveur distant Publisher, son adresse IP et le port SQL Server, dans les deux branches “Aliases”.
Cela permettra de se connecter aux serveurs SQL distants en utilisant uniquement des noms et non des adresses IP. Il est fondamental d’ouvrir le port SQL Server (ici on peut voir celui par défaut) sur les serveurs. Lorsque vous cliquez sur “Rechercher SQL Server Publisher”, il vous sera demandé de vous connecter au serveur éditeur, puis la fenêtre d’authentification standard de SQL Server vous demandera :
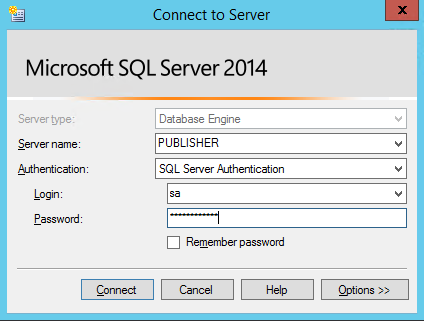
Une fois authentifié, nous pourrons voir la publication que nous avons créée sur l’éditeur, puis la sélectionner et continuer :
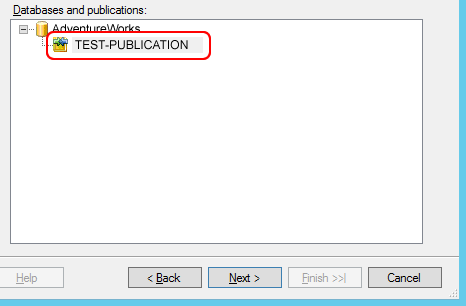
Passons à l’étape suivante et gardons les options par défaut :
Dans la fenêtre suivante, sélectionnons la base de données à synchroniser. Nous pouvons créer cette base de données sur l’abonné simplement en restaurant une copie de la base de données principale que nous avons sur l’éditeur.
Comme le montre l’image, il y a à la fois le nom du serveur de l’abonné (nous l’avons appelé “SUBSCRIBER” dans cet exemple) et le nom de la base de données.
Par la suite, définissons les informations d’identification requises. Nous utiliserons le compte Administrateur Windows dans le premier panneau et le compte SQL Server dans le second (comme nous l’avons déjà fait avec l’éditeur).
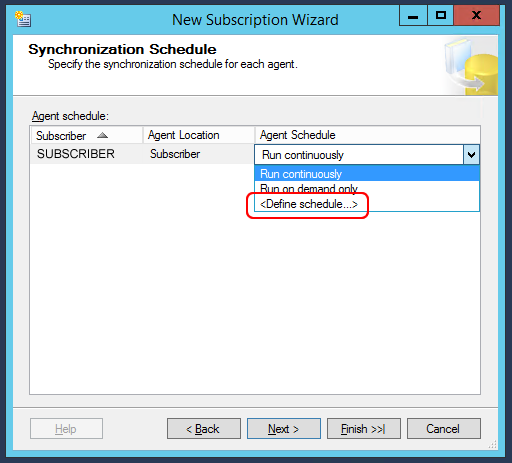
Passons à l’étape suivante, qui consiste à définir QUAND exécuter la synchronisation des données. Il est possible de le configurer en temps réel (synchronisation continue) ou de le programmer en définissant un intervalle de temps. C’est juste une programmation Windows standard. Si nous avons besoin de synchroniser continuellement les données, nous pouvons également choisir un intervalle de 10 secondes. Sinon, un intervalle de minutes / heures / jours sera également correct.
Dans la fenêtre suivante, définissons l’abonnement à initialiser immédiatement :

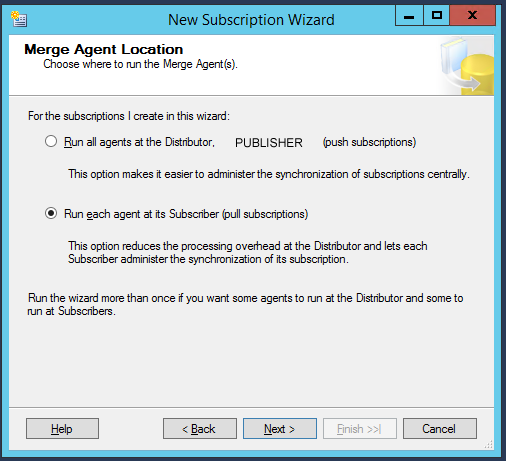
Enfin, configurons l’abonné pour qu’il s’exécute également en mode serveur: cela signifie que l’abonné récupérera non seulement les données de l’éditeur, mais lui enverra également ses propres données, ce qui implique une synchronisation bidirectionnelle. Gardons l’option par défaut pour la priorité de résolution de conflit :
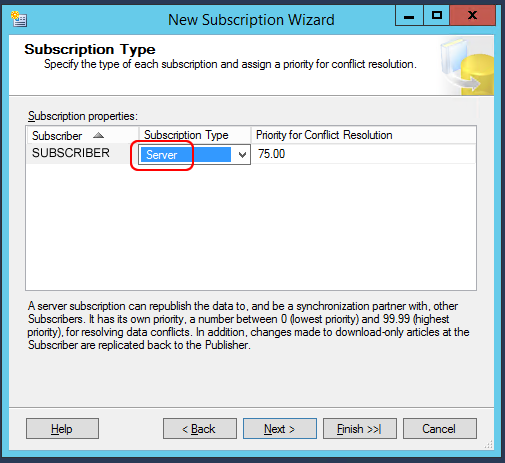
Allons ensuite à la dernière fenêtre et cliquez sur “Terminer” pour créer l’abonnement et démarrer la synchronisation :
Vérifions si la synchronisation fonctionne correctement en ouvrant la fenêtre d’état de la synchronisation (voir image ci-dessous) :
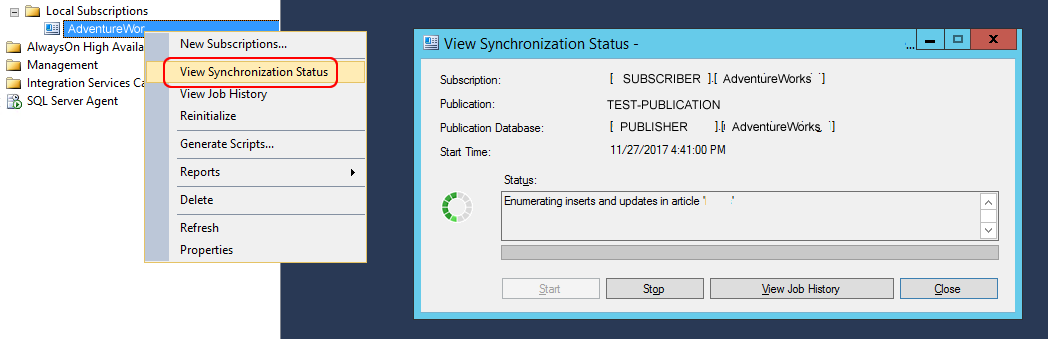
La synchronisation fonctionne correctement !
Après avoir suivi toutes les étapes de ce tutoriel, nous avons correctement configuré une synchronisation de données entre deux (ou plus) SQL Server distants sans aucun problème.
Vous trouverez également de la documentation pour optimiser et améliorer la réplication sur le site de Microsoft :
(Anglais, Italien, Allemand, Espagnol, Portugais - du Brésil)
PLEASE NOTE: if you need technical support or have any sales or technical question, don't use comments. Instead open a TICKET here: https://www.iperiusbackup.com/contact.aspx
**********************************************************************************
PLEASE NOTE: if you need technical support or have any sales or technical question, don't use comments. Instead open a TICKET here: https://www.iperiusbackup.com/contact.aspx
*****************************************