
In questo articolo andremo ad approfondire qual è la differenza tra una immagine Docker e un container e a realizzare un nostro Dockerfile per meglio comprendere tutte le varie fasi della virtualizzazione a container di Docker.
Abbiamo già parlato di questo sistema in un precedente tutorial in cui abbiamo imparato come si installa Docker.
Ma perché parlare di immagini e di container?
Docker image e container
Per meglio chiarire quali sono le differenze tra immagini e container, ragioniamo per analogia ad un linguaggio object oriented, dove la classe rappresenta l’immagine e l’istanza di quella classe, l’oggetto, è il container.
La stessa immagine può dar vita a più container.
La virtualizzazione a container si basa quindi fondamentalmente sulle immagini, ovvero i file reperibili sul Docker Hub e utilizzate per la creazione e l’inizializzazione di una applicazione in un nuovo contenitore Docker.
Ogni immagine è definita da un Dockerfile, un file di configurazione che contiene tutti i comandi che un utente deve eseguire per assemblare l’immagine.
I livelli del Dockerfile
Il dockerfile è un potente strumento per la definizione delle immagini grazie anche alla sua struttura a livelli, che contiene l’indicazione di comandi, librerie da utilizzare e dipendenze.
Può succedere che alcuni livelli siano presenti in più progetti e questa caratteristica garantisce il riuso dei livelli già scaricati e di conseguenza una garanzia sulle performance oltre che, non meno importante, un risparmio di tempo e spazio fisico.
Ammettiamo ad esempio di avere necessità di utilizzare le immagini di due rdbm quali postgresql e mysql (o mariadb).
Per prima cosa, ricerchiamo con il comando docker search le immagini ufficiali contenute sul dockerhub per questi due sistemi e prendiamo l’immagine ufficiale.
#docker search postgresql
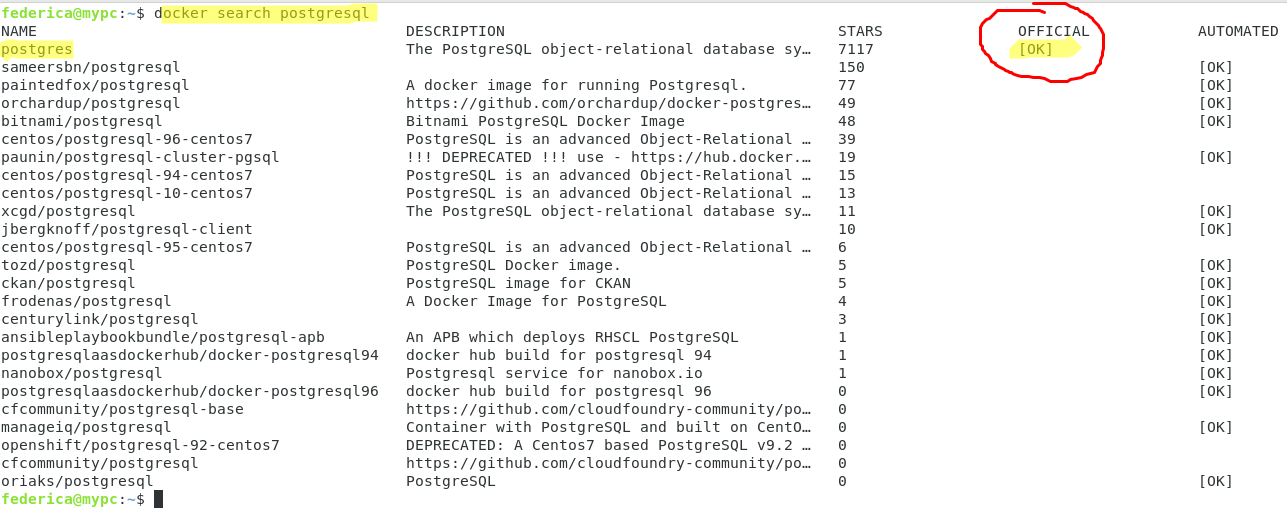
#docker search mysql

In questo secondo caso possiamo scegliere sia mysql che mariadb.
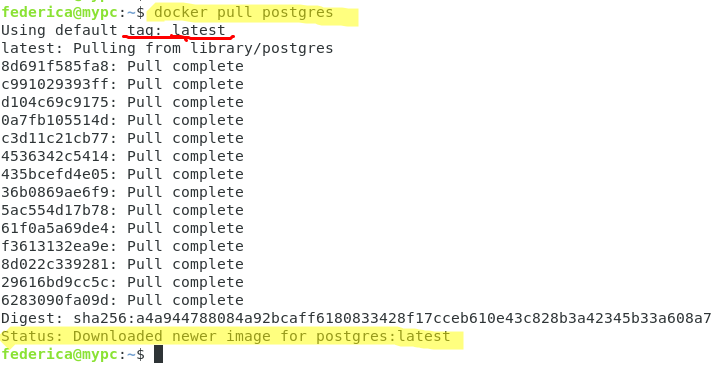
Scegliamo quest’ultimo e con il comando docker pull, scarichiamo le immagini in locale dal DockerHub.
# docker pull postgres
#docker pull mariadb
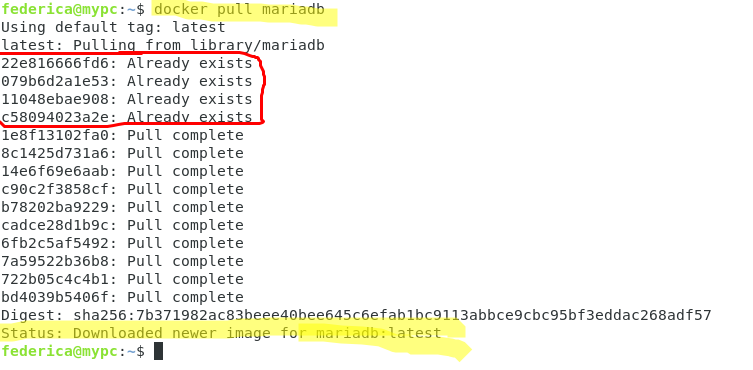
Notiamo che lo status finale indica il corretto download delle immagini nelle versioni latest (identificato dal tag di default) e che in entrambi i casi sono composte di 14 layer distinti.
Osserviamo però che nel caso di mariadb, i primi 4 layer sono indicati con la dicitura “Already exists“.
Ciò significa che questi erano già stati scaricati in un precedente pull e non è quindi necessario riscaricarli.
Ognuno di questi layer è distinto da un identificativo mentre la penultima stringa Digest rappresenta univocamente l’immagine appena scaricata come hash dell’immagine stessa.
Per comprendere meglio questo aspetto dei layer di Docker, approfondiamo come si costruisce un DockerFile.
Costruiamo un DockerFile
È possibile, se necessario, crearsi i propri Dockerfile, aggiungendo livelli ad una base image, cioè un’immagine che rappresenta la base da cui partire, oppure da una immagine vuota nel caso di necessità di avere estrema libertà nella gestione.
In entrambi i casi la prima riga conterrà il comando FROM che indicherà la base image (scratch nel caso di immagine vuota).
Facciamo l’esempio di un semplice Dockerfile derivato da una immagine ufficiale ubuntu.
Creiamo il nostro Dockerfile con l’editor preferito e aggiungiamo le seguenti righe:
FROM ubuntu RUN apt-get update RUN apt-get install --yes apache2 COPY index.html /var/www/html/index.html
Al primo livello FROM ubuntu, si aggiungono 3 livelli che rappresentano i comandi che vogliamo aggiungere.
Eseguiamo il comando build per costruire l’immagine come descritta sul file nel seguente modo:
#docker build .
Ricordandoci il punto (.) che indica la directory corrente in cui docker cerca un dockerfile esattamente con questo nome.
Come si vede dalle immagini seguenti l’operazione di build è formata da 4 step, che corrispondono ai 4 livelli della nostra immagine.
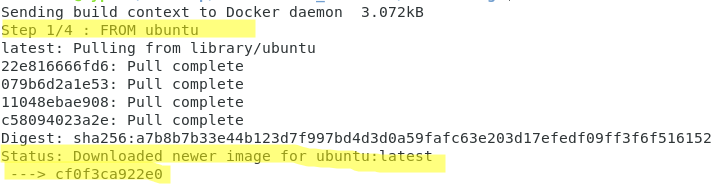
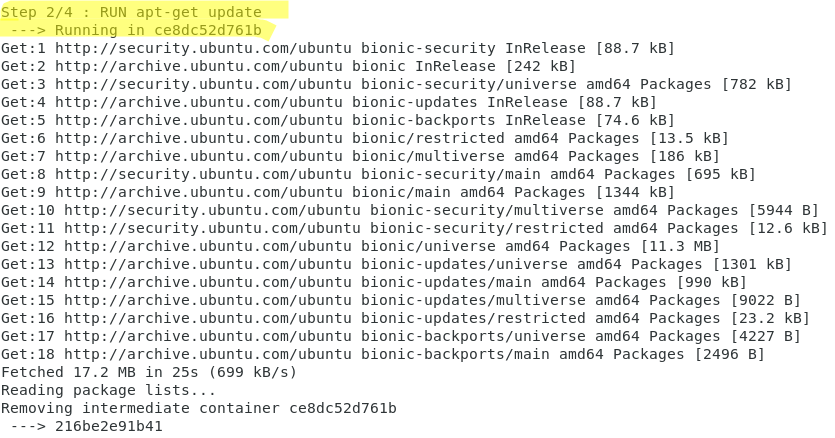


In realtà verranno costruiti dei livelli intermedi, che hanno la funzione di cache nelle esecuzioni successive, come è possibile vedere dal comando:
#docker images -a

Le immagini identificate con <none> nel nome del repository sono quelle intermedie.
Per comprendere meglio, proviamo a rieseguire adesso il comando
#docker build .
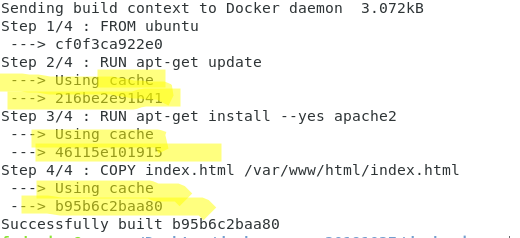
É facile verificare che adesso il build dell’immagine è molto più veloce e riutilizza immagini che ha già in cache.
L’immagine 46115e101915 ad esempio è quella che viene riutilizzata nello step 3/4.
I container
Finora abbiamo parlato di come scaricare una image, o come costruirsi e implementarne una propria.
Ma è con il comando docker run che tutto davvero prende forma.
#docker run --rm --name ubuntu_apache -it ubuntu
![]()
Questo comando infatti permette di istanziare un container sull’immagine appena creata.
Le opzioni scelte in questo caso sono quelle riferite all’interattività (-i), alla allocazione di una console TTY (-t) e alla possibilità di rimuovere direttamente il container una volta usciti (–rm).
Sulla documentazione ufficiale di Docker si trova la lista di tutte le opzioni per il comando run.
Mentre l’immagine è costituita da una serie di layer tutti in modalità in sola lettura, il container aggiunge un top layer (chiamato anche container layer) in modalità lettura-scrittura.
E ogni volta che un nuovo container viene istanziato sulla stessa immagine, un nuovo layer sempre diverso viene aggiunto a formare nuovi contenitori.
Se vogliamo avere una lista dei container, attivi e non, possiamo eseguire il comando
#docker ps -a

La comodità di utilizzare i container è che è possibile facilmente e velocemente costruire un ambiente di sviluppo o di test quante volte vogliamo.
Uscendo dalla console con il comando exit, il container, per mezzo dell’opzione –rm, non esisterà più.
Proviamo adesso ad utilizzare il comando:
#docker run --name ubuntu_apache -it ubuntu
senza la precedente opzione per la rimozione.

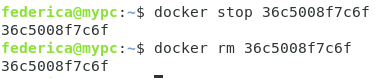
A questo punto, se volessimo rimuoverlo manualmente dovremo usare il comando
#docker rm
seguito dall’id.
Ma non prima di averlo fermato.
Quindi la corretta sequenza dei comandi è la seguente:
Se volessimo invece semplicemente riavviare il container precedentemente fermato, il comando da usare è
#docker start
e nel nostro caso di esempio sarebbe:
![]()
Conclusioni
In questo articolo abbiamo avuto modo di comprendere da alcuni esempi l’estrema semplicità con cui è possibile implementare ambienti perfettamente funzionanti, replicabili su qualsiasi macchina sfruttando la scalabilità del sistema a livelli delle immagini docker.
In seguito affronteremo anche come incrementare la potenzialità di questo strumento con meccanismi potenti come Docker-compose e Docker-swarm.
Credits images:
metal PNG Designed By Mark1987 from Pngtree.com
Docker Icon made by Freepik from www.flaticon.com
PLEASE NOTE: if you need technical support or have any sales or technical question, don't use comments. Instead open a TICKET here: https://www.iperiusbackup.com/contact.aspx
**********************************************************************************
PLEASE NOTE: if you need technical support or have any sales or technical question, don't use comments. Instead open a TICKET here: https://www.iperiusbackup.com/contact.aspx
*****************************************